

Prerequisite: Learn Hash Tables
🔦 This concept is easier to understand if you have created a hash function while designing a hash table. If not, check out this quick guide created by w3schools.com that explains the data structure to get up to speed quickly: Hash Tables on W3Schools
❓ When is consistent hashing utilized?
In distributed systems (caches like Redis cluster, databases like Cassandra/DynamoDB, CDNs, load balancers), we shard data across many servers. However, there is a problem with the traditional approach using a standard hash-function.
Modular hashing works great when N(servers) are fixed forever.
🚨 The nightmare: Adding/removing servers (scaling, failures, maintenance)
-N changes → modulus changes → almost every key remaps!
-For N=100 → ~99% of keys move → massive cache misses, DB thrashing, downtime spikes, rebalancing storms. Basically, incorrect retrievals.
⭕ INTRODUCING CONSISTENT HASHING!
🗝️ Key Idea: Don't use the standard hash function approach of hash(key) % N.
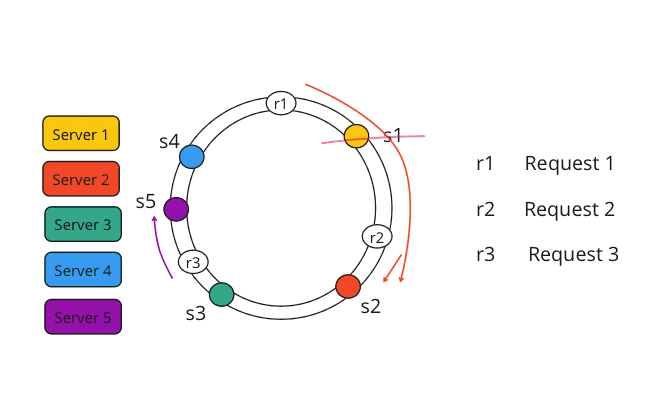
✅ Use a fixed, huge hash space visualized as a ring (a giant circle of possible hash values, like 0 to 232-1). You may want to reference this so you understand the idea. (See diagram below)
Consistent Hashing Ring (Basic Concept)
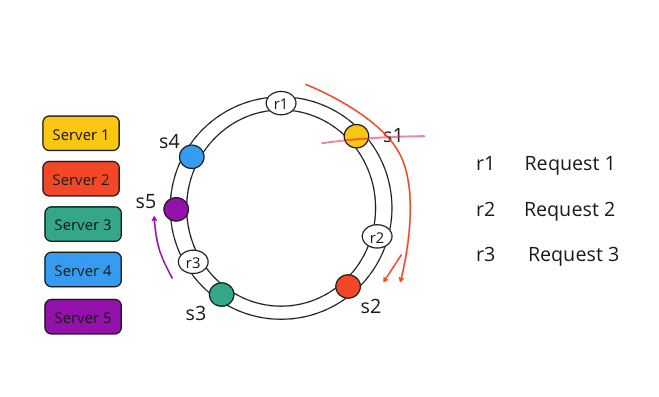
⚖️ 🤹♀️ Rather than losing accuracy, this concept introduces consistency and reliability in connecting to the correct servers, even in the event of a system failure.
🛞 How it works (basic version):
- Hash servers onto the ring: Hash each server's ID (IP, name, etc.) → place it at a point.
- Hash keys onto the ring: Same hash function for data keys.
Ownership rule: For a key, go clockwise from its position → first server you hit owns it (and its replicas if needed). - When a server dies or a new one joins → only keys in the "arc" between the departed/added server and its clockwise neighbor move (~1/N of total keys on average). Way better than ~100%!
⚠️ Here are some problems with the hash ring approach:
- 🔺 Uneven load: Hash functions aren't perfectly uniform → some servers own huge arcs (hotspots!).
- 🔺 Failure pain: One server's entire load dumps onto its single clockwise neighbor → instant overload.
🛡️ The real-world fix: Virtual Nodes (vnodes / replicas)
- Each physical server gets many (50–256+) points on the ring.
- Hash variations like "server1-vn1", "server1-vn2", "server1-vn3", etc.
- More vnodes = smoother distribution, better balance.
- When a server fails → its load spreads across many neighbors, not just one.
- You can even weight vnodes by server capacity (stronger servers get more vnodes).
➗ Conclusion:
Consistent hashing minimizes data movement during scaling; unlike modular hashing, only 1/N of keys are reshuffled. Basic rings can cause hotspots, so systems like Amazon DynamoDB use virtual nodes to ensure even distribution and spread failure impact.
💡 In interviews, lead with the ring concept, then pivot to vnodes and replication as the pro standard for high availability.
Summary
Thank you for reading my blog post!
To continue learning the fundamentals of System Design, the next important fundamental to learn is understanding...
Make sure to check out the additional blogs here for materials to help you throughout your learning journeys!